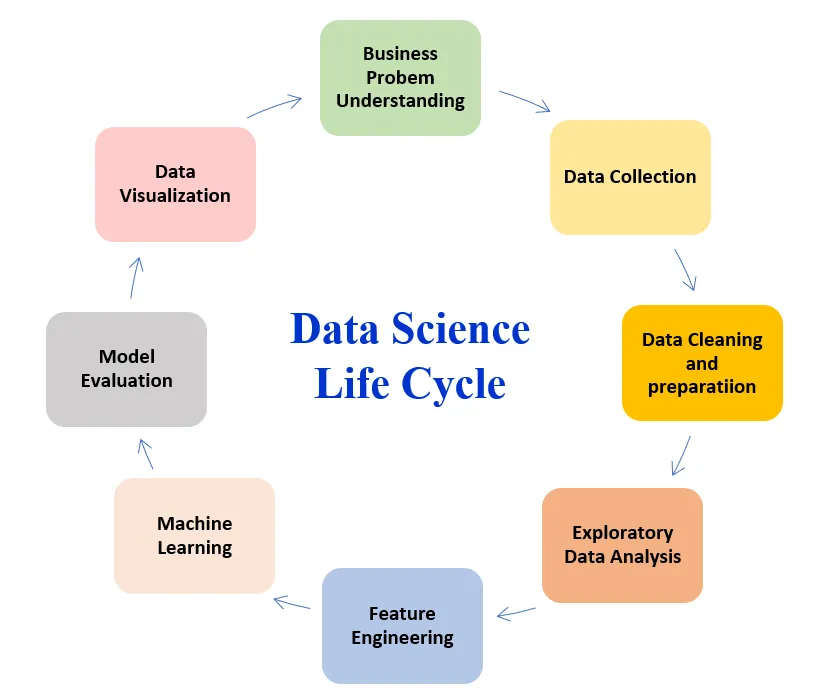
Data science is the study of data to extract meaningful insights for various applications. It is a multidisciplinary approach that combines principles and practices from the fields of mathematics, statistics, artificial intelligence, and computer science or engineering and domain expertise to analyze interpret, and derive meaningful information from large amounts of data (Big Data). It is a multidisciplinary field that involves extracting knowledge and insights from large volumes of data using various techniques, tools, and algorithms. Here are some key aspects and components of data science:
-
Data Collection: Data scientists start by collecting relevant data from various sources, such as databases, APIs, web scraping, sensors, or surveys. They ensure the data is accurate, complete, and suitable for analysis.
-
Data Cleaning and Preparation: Raw data often contains errors, missing values, inconsistencies, or noise. Data scientists clean and preprocess the data by removing duplicates, handling missing values, standardizing formats, and transforming variables into a suitable representation for analysis.
-
Exploratory Data Analysis (EDA): EDA involves examining the data visually and statistically to gain insights, identify patterns, and understand the relationships between variables. Techniques such as summary statistics, data visualization, and correlation analysis are used during this phase.
-
Feature Engineering: Feature engineering involves transforming the raw data into more meaningful and informative features that can enhance the performance of machine learning algorithms. It includes techniques such as feature scaling, dimensionality reduction, and creating new derived features.
-
Machine Learning: Machine learning is a core component of data science. It involves training models on historical data to make predictions or uncover patterns in new, unseen data. Supervised learning, unsupervised learning, and reinforcement learning are common approaches used in machine learning.
-
Model Evaluation and Selection: Data scientists evaluate the performance of machine learning models using appropriate evaluation metrics and validation techniques. They select the best-performing model based on accuracy, precision, recall, F1 score, or other relevant criteria.
-
Model Deployment: Once a model is trained and evaluated, data scientists deploy it to make predictions on new data or integrate it into a larger system or application. Deployment can involve using APIs, creating dashboards, or embedding the model into production systems.
-
Continual Learning & Improvement: Data scientists constantly iterate and improve their models and analyses as new data becomes available or as new techniques and algorithms emerge. They also monitor model performance over time and refine their approaches to maintain accuracy and relevance.
-
Communication and Visualization: Data scientists play a crucial role in communicating their findings and insights to stakeholders, decision-makers, or non-technical audiences. They use data visualization techniques to present complex information in a clear and accessible manner.
-
Ethical Considerations: Data scientists must consider ethical and privacy implications when working with data. They need to ensure compliance with legal and regulatory requirements, protect sensitive information, and avoid biased or unfair outcomes.
Data science has broad applications across industries, including finance, healthcare, marketing, cybersecurity, transportation, and many others. It enables the organizations to leverage data-driven decision-making, uncover hidden patterns, improve processes, and gain a competitive edge in the era of big data.
Data Science Certificate Course Programme at Orbital Africa
This course is offered to those who are above 18 years, are ongoing or have completed university or college in any field, and have some knowledge or background in mathematics and statistics. The data science course programme will cover the following topics:
Introduction to Data Science:
- Overview of data science and its applications.
- Introduction to key concepts, terminology, and tools used in data science.
- Understanding the data science process and workflow.
Data Manipulation and Analysis:
- Data cleaning and preprocessing techniques.
- Exploratory data analysis (EDA) and visualization.
- Statistical analysis and hypothesis testing.
Programming and Data Handling:
- Programming languages commonly used in data science, such as Python or R.
- Data handling and manipulation using libraries and packages like pandas and NumPy.
- Working with data in different formats, such as CSV, JSON, or SQL databases.
Machine Learning:
- Supervised learning algorithms (such as the linear regression, logistic regression, decision trees, random forests, support vector machines).
- Unsupervised learning algorithms (e.g., clustering, dimensionality reduction).
- Evaluation metrics and techniques for assessing model performance.
- Techniques for model selection, optimization, and regularization.
Data Visualization:
- Creating meaningful visual representations of data using libraries like Matplotlib or ggplot2.
- Design principles for effective data visualization.
- Interactive visualization using tools like Tableau or D3.js.
Big Data and Distributed Computing:
- Handling large-scale data sets using distributed computing frameworks like Hadoop or Spark.
- Processing and analyzing big data using tools like Apache Spark or Apache Hadoop.
Deep Learning and Neural Networks (optional):
- Introduction to deep learning concepts and neural networks.
- Popular deep learning architectures, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
- Practical implementation of deep learning models using frameworks like TensorFlow or PyTorch.
Real-world Projects and Case Studies:
- Applying data science techniques to real-world datasets and problem-solving.
- Working on projects that involve data cleaning, exploratory analysis, modeling, and visualization.
- Gaining hands-on experience in end-to-end data science workflows.
 It’s important to note that the depth and breadth of topics covered in a data science course can vary. Some courses may have a broader overview, while others may dive deeper into specific areas. The duration of the course can also vary, ranging from a few weeks to several months, depending on the level of detail and the intensity of the program.
It’s important to note that the depth and breadth of topics covered in a data science course can vary. Some courses may have a broader overview, while others may dive deeper into specific areas. The duration of the course can also vary, ranging from a few weeks to several months, depending on the level of detail and the intensity of the program.
Before enrolling in a course, it’s beneficial to review the course syllabus, prerequisites, and reviews to ensure it aligns with your learning goals and expectations. Consider your prior knowledge, programming skills, and specific areas of interest within data science to choose a course that suits your needs. For more details, refer to Our Certificate Courses and Course Catalogue for more details.
Ad: Explore the world with Expedia

Flewflew: AI solutions provider in Africa

OrbiCollect: Mobile mapping made easier!

NSE Stock Market: Buy & Sell Shares

Join Binance and Let us win together!

AGM 6th Edition: Jan-Apr 2025
